

Eden od temeljev identifikacijske in varnostne tehnologije - Dinamični nadzor dostopa (dinamični nadzor dostopa) v sistemu Windows Server 2012 je funkcionalen Infrastruktura klasifikacije datotek (FCI - Infrastrukture za razvrščanje datotek). FCI se uporablja na datotečnih strežnikih organizacije in omogoča ustvarjanje novih lastnosti in atributi(Lastnosti datoteke za razvrščanje datotek) za klasifikacija datotek. FCI omogoča samodejno razvrščanje datotek glede na vsebino datoteke ali imenik, v katerem se nahajajo; upravljajte datoteke (na primer obdobje, v katerem je možen dostop do datoteke); ustvari poročila, ki prikazujejo porazdelitev lastnosti klasifikacije na datotečnem strežniku. Datoteke na podlagi ključnih besed ali vzorcev se lahko samodejno razvrstijo na primer kot zaupne ali vsebujejo osebne podatke. Vendar lahko uporabnik (lastnik) brez uporabe FCI datoteke ročno razvrsti tudi.
FCI je element dinamičnega nadzora dostopa, ki datoteke razvršča tako, da jim dodeli oznake, od katerih je odvisna uporaba pravilnikov DAC..
Prvič tehnologija Infrastruktura klasifikacije datotek Predstavljeno v sistemu Windows Server 2008 R2. Katere priložnosti je ponudila? S FCI je možno implementirati različne scenarije obdelave dokumentov v shrambah datotek (vključno s tistimi, ki vsebujejo zaupne podatke): zbiranje, šifriranje, prenos, arhiviranje, pošiljanje po poti in brisanje datotek. Z uporabo FCI lahko na primer implementirate skript, ki vam omogoča, da datoteke samodejno premaknete iz dragega pomnilnika v cenejše in počasnejše na podlagi klasifikacije datotek ali, na primer, po določenem času datoteke samodejno naredite nedostopne..
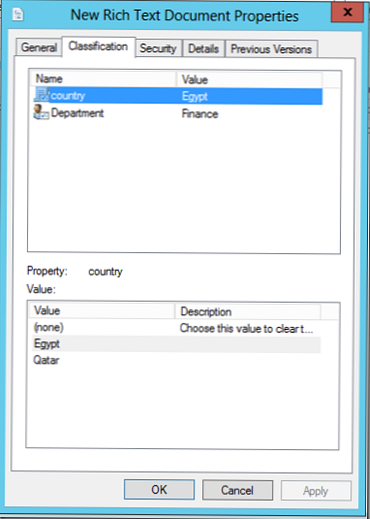
Spodnji posnetek zaslona prikazuje primer datoteke, ki je razvrščena kot pripada državi Egiptu in oddelku za finance. Atributi klasifikacije so lahko absolutno karkoli: na primer prednost, zasebnost, lokacija, organizacija itd..
Kako ročno razvrstiti datoteko ali imenik
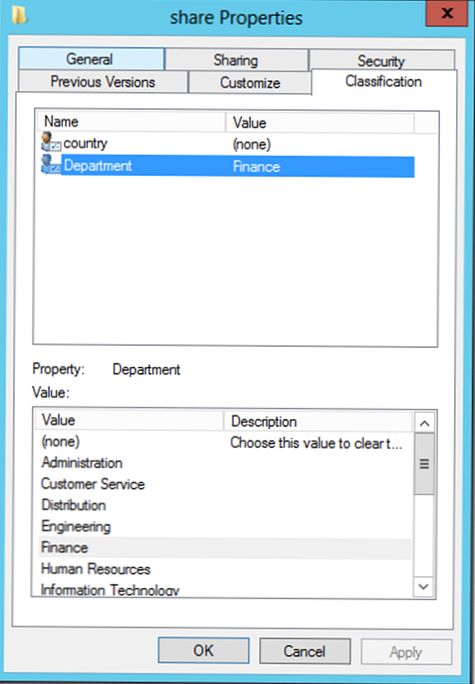
Datoteke in imenike lahko razvrstite ročno, tako da odprete okno lastnosti predmetov in izberete "Razvrstitev". V našem primeru lahko na spustnem seznamu vnaprej določenih vrednosti izberete druge vrednosti za atribute države in oddelka..
Samodejno razvrščanje
Če želite konfigurirati samodejno razvrščanje predmetov v operacijskem sistemu Windows Server 2012, morate za namestitev vloge uporabiti konzolo upravitelja strežnika Datotečni strežnik (datotečni strežnik).
Z namestitvijo komponente Upravitelj virov datotek (FSRM), odprite ustrezno konzolo MMC in med znanimi skupinami za kvote, pregled datotek, upravljanje datotek boste videli novo podpoglavje Upravljanje klasifikacije (klasifikacija), ki je sestavljena iz dveh sklopov:
- Lastnosti razvrstitve - služijo za ustvarjanje klasifikacijskih atributov (v našem primeru so to atributi države in oddelka, ki imajo globalni status, ker so objavljeni v AD)
- Pravila razvrščanja - pravila samodejnega razvrščanja

Če želite nastaviti samodejno razvrščanje dokumentov, morate ustvariti klasifikacijsko pravilo.
Eden od načinov za organizacijo samodejne razvrstitve datotek glede na lokacijo je lastnost klasifikacije - MapaUporaba. To je vnaprej določena lastnost, shranjena v razdelku Lastnosti klasifikacije. Privzeto določa 4 vrste podatkov:
- Podatki o aplikaciji - Podatki o aplikaciji
- Varnostne kopije - Varnostne kopije podatkov
- Skupinski podatki - Skupinski podatki
- Uporabniške datoteke - uporabniške datoteke
Tu lahko ustvarite svoje vrste podatkov..
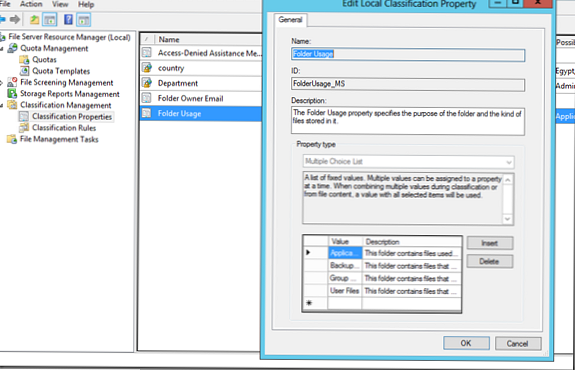
Tu bomo ustvarili svoje vrste map za finančni (finančni) in inženirski oddelek (inženiring), nato pa moramo določiti, katere datoteke pripadajo enemu oddelku (vrsta podatkov). Če želite to narediti, kliknite na prazno mesto v konzoli FSRM pod RazvrstitevLastnosti in izberite SetMapaUpravljanjeLastnosti
Izberite lastnost MapaUporaba in določite mape, ki jih bo uporabljal vsak oddelek, ali vsebujejo določeno vrsto podatkov. Vendar je treba razumeti, da v tem primeru ni klasifikacija datotek, ki je konfigurirana (pozneje jo bomo konfigurirali), bomo določili lastništvo map, ki jih bomo uporabili v razvrstitvenem pravilu
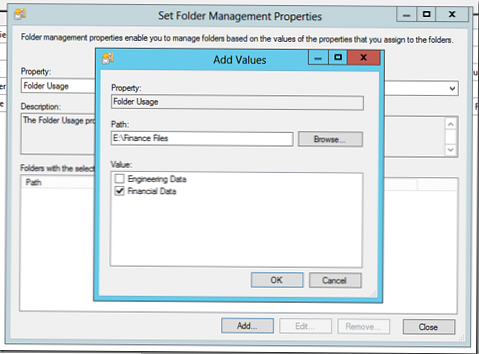
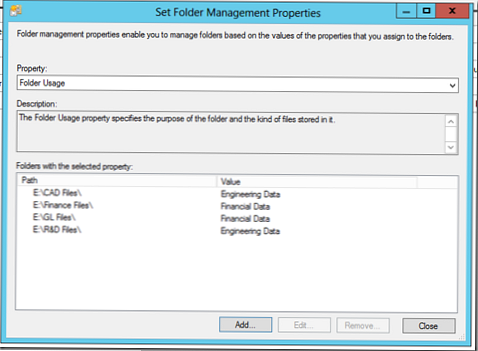
Postavili smo ga takole:
Ustvari pravilo razvrstitve podatkov
V razdelku je prišel čas RazvrstitevPravila ustvarite novo pravilo (kontekstni meni Ustvari pravila razvrstitve):
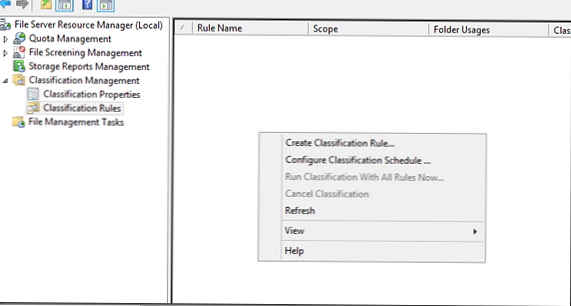
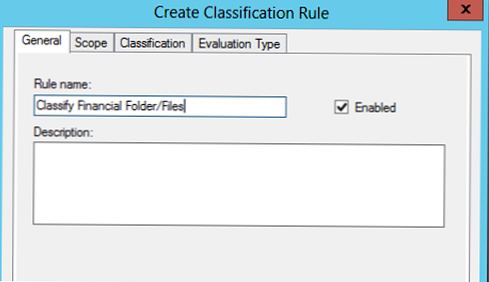
Navedite ime pravila (ustvarili bomo pravilo za razvrščanje datotek, ki pripadajo finančnemu oddelku).
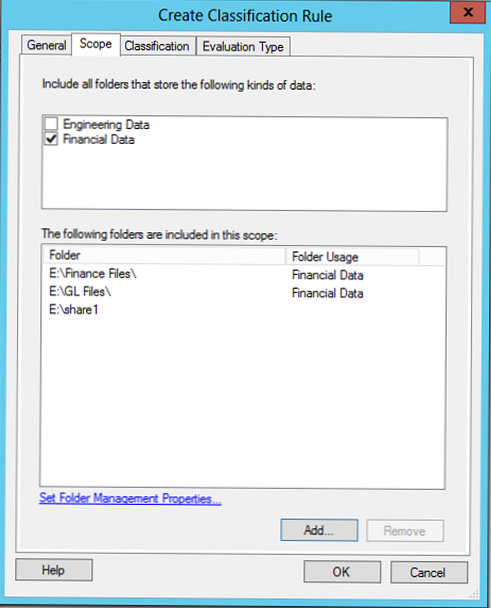
Zavihek Področje uporabe navedemo imenike, ki jih moramo upoštevati pri razvrščanju, izbrali bomo pravilo, ustvarjeno prej FinančniPodatki (samodejno doda vse prej izbrane mape), lahko tudi imenike dodate ročno (v primeru je E: \ share1).
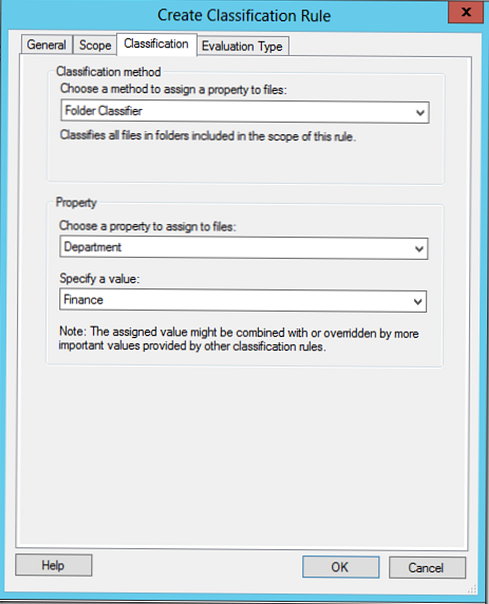
Zavihek Razvrstitev Izberete lahko enega od dveh načinov razvrščanja:
- Klasifikacija map - klasifikacija na osnovi imenika (atributi veljajo za vse datoteke imenika)
- Razvrstitev vsebine - razvrstitev po vsebini datoteke. V tem primeru se vse datoteke v imeniku iščejo po ključnih besedah, vzorcih ali običajnih izrazih (številke projektov, kreditne kartice, identifikatorji oddelkov itd.).
Na zaslonu je prikazano pravilo o razvrščanju, ki temelji na imenikih, v nadaljevanju bo obravnavano pravilo o razvrstitvi po vsebini.
Zavihek Vrsta vrednosti vrednotenja Naveden je postopek za uporabo in ponovno uporabo klasifikacijskih pravil za datoteke. V spodnjem primeru smo navedli, da lahko sistem prepiše trenutno klasifikacijo, s čimer zagotavljamo, da bo klasifikacija uporabnikov prevladala s korporativnim pravilom.

V naslednjem razvrstitvenem pravilu bomo izdelali klasifikacijsko pravilo glede na vsebino datoteke:
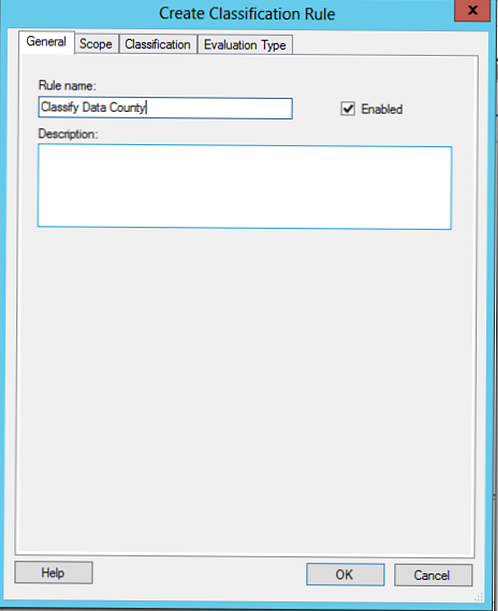
To pravilo razvršča podatke po državah, zato bomo vanj dodali kataloge inženirskih in finančnih oddelkov.
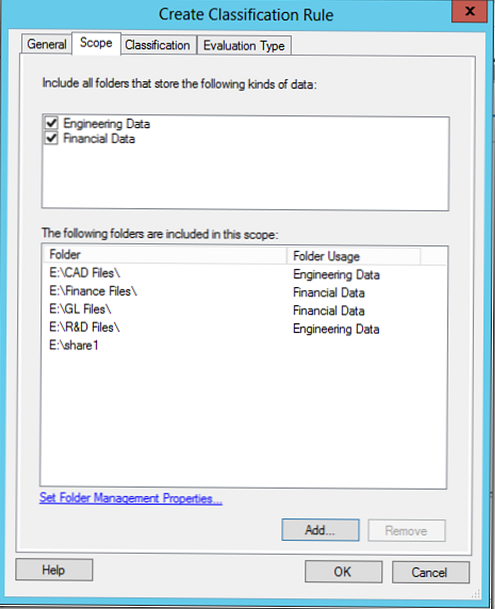
V tem razvrstitvenem pravilu bomo na podlagi vsebine datoteke poskušali razvrstiti podatke, povezane z državo Egipt.
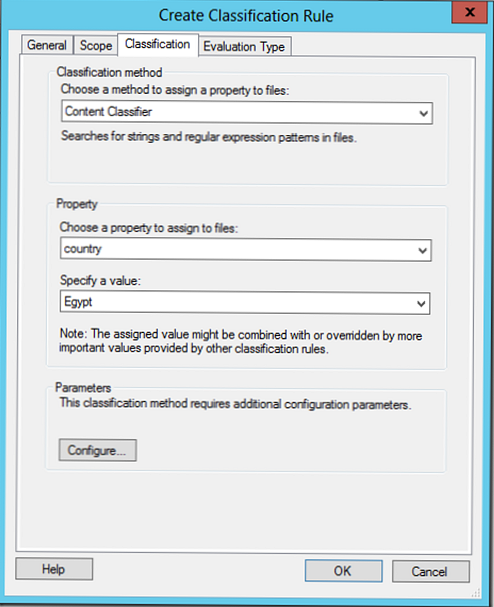
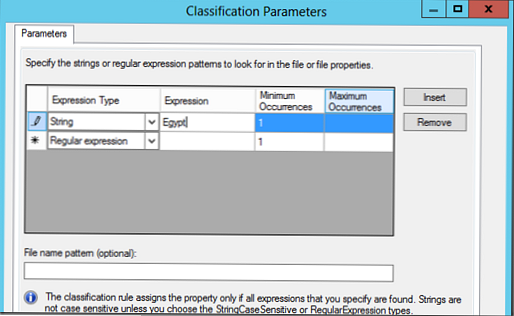
V razdelku Parametri izberite Konfigurirajte. V oknu, ki se prikaže, lahko iščete na podlagi običajnih izrazov, niza ali niza, ki razlikuje veliko in malo črko..
Z regularnimi izrazi lahko iščete po besedilnih dokumentih (vključno z datoteko tiff) po različnih merilih, na primer:
- Prisotnost korenin v besedi, ne da bi bili pozorni na primere in pripone
- Prisotnost besed ali stavkov v naključnem vrstnem redu
- Razpoložljivost podatkov v določeni obliki, kot so številke kreditnih kartic, telefonske številke, podatki o potnem listu ali e-poštni naslovi
- Pogoji za sestanek za določeno število sestankov zahtevanih podatkov v datoteki (na primer vsaj 3 kreditne kartice ali telefonske številke)
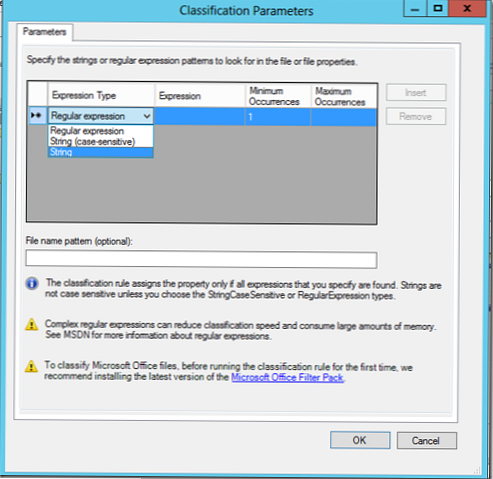
V našem primeru bomo iskali dokumente s ključno besedo Egypt, in če jo najdemo, bi bilo treba datoteko razvrstiti po tem pravilu (v dokumentu lahko določite najmanjše in največje število pojavnosti ključne besede).
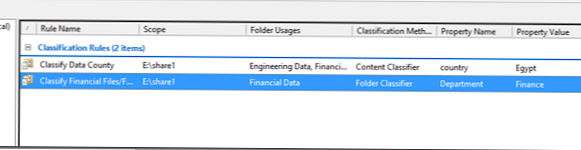
Tako smo ustvarili dve klasifikacijski pravili:
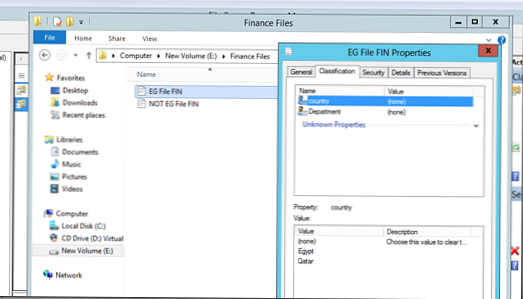
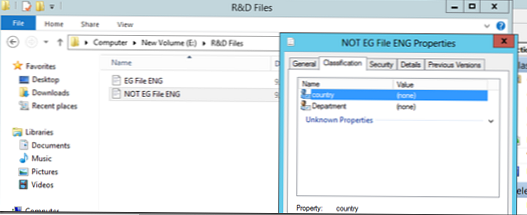
Zdaj poskusimo zagnati samodejno razvrščanje datotek. Recimo, da imamo dve datoteki, od katerih ena vsebuje besedo Egipt, druga pa ne. Te datoteke so postavljene v mape »Finančne datoteke« in »Datoteke za raziskave in razvoj«, kot lahko vidite, da trenutno niso razvrščene..
Zaženite naša pravila razvrščanja (Izvedite klasifikacijo z vsemi pravili):
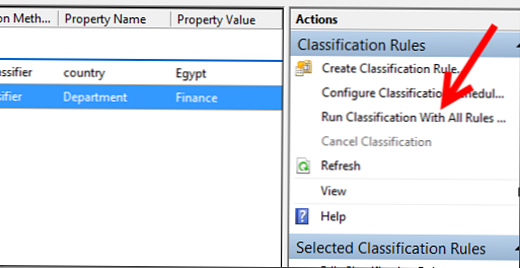
Rezultate pravil lahko najdete v poročilih v poročilih..

Kot vidite, je vse delovalo pravilno, datotekam je bila dodeljena pravilna država, ključni besedi pa atribut Finance za celotno vsebino kataloga finančnega oddelka.
Na tej stopnji niso bile izvedene nobene operacije z zaupnimi datotekami, temveč so bile preprosto označene s potrebnimi atributi. V prihodnosti lahko na podlagi razvrstitve datotek z njimi izvajate različne operacije, zlasti šifrirate datoteke z uporabo AD RMS (primer uporabe je opisan v članku Šifriranje datotek z uporabo AD RMS, ki temelji na infrastrukturni razvrstitvi datotek Windows Server 2012) ali nadzor dostopa do njih prek sistema Windows Dinamični nadzor dostopa strežnika 2012. Te vidike bomo obravnavali v naslednjih člankih v seriji..

{kind=link}